Last week I received an email in my inbox about a hackathon hosted by the awesome folks over at Amberdata. They are a provider for on-chain data and cover a large variety of blockchains – including Ethereum, Bitcoin, and Stellar. I have met the developers in the team in late 2018 when I was looking for my next gig in the Ethereum ecosystem and long before that I was stunned by the large variety and volume of data they are handling.
I have already written before about how consuming raw blockchain data with commodity hardware comes close to drinking from a fire hose. There is an inherent need for making the data easily consumable – first programmatically, and with that in a manner that focuses on user experience.
Amberdata’s API covers the programmatic aspect by providing three categories of endpoints: REST, RPC, and Websockets. These are surfaced through raw API interaction, and an in-house JavaScript library they have developed – web3data-js.
Friends and colleagues will know that I am a JavaScript survivor with a passion for Python, and with my girlfriend being out of town for a week, and the Coronavirus ravaging my region, going out was not the best idea to begin with. So let’s bring blockchain data to the Python world and migrate the official library!
Starting Out
Hackathon projects, which especially the Ethereum system has lots of, typically follow the same steps:
- Go to a kickass blockchain event such as ETHDenver, EthCC, or an Ethereal Summit
- Pick a project that you think is worth hacking on.
- Fall into a 3-day caffeine-fuelled coding rage and bring it to life.
- Publish, drop maintenance immediately, rinse and repeat.
My goal for this hackathon was different. What if instead of building a ton of hacky with features I cannot maintain, I would instead focus on building maintainable software that people can actually use as a daily driver?

So I sat down, read through the JS library and came up with a small roadmap that I would focus on for the coming three days. After all, the caffeine-fuelled coding rage part of the standard hackathon approach is something we don’t have to drop necessarily.
Implementation
The implementation process went smoothly. I lost a few hours playing around with dynamic method binding. This would have allowed the client to dynamically register API call methods based on whether the specified chain is supported by the endpoint. In web3data-js is looks something like this:
/**
* Appends blockchain specific methods to an instance of Web3Data under it's
correct namespacing.
*
* @param _this - Instance of Web3Data to append methods.
* @param includeMethods
* @private
* @example
*/
const methodFactory = (_this, includeMethods) => {
Object.keys(includeMethods).forEach(namespace => {
getMethods(Object.getPrototypeOf(_this.web3data[namespace])).forEach(
method => {
if (includeMethods[namespace].includes(method)) {
_this[namespace] = _this[namespace] ? _this[namespace] : {}
_this[namespace][method] = _this.web3data[namespace][method].bind(
_this
)
}
}
)
})
return _this
}
This is also possible in Python using the MethodType class. It allows you to dynamically bind functions to classes as methods. The disadvantage: This is done during runtime, so while an interactive shell such as ipython would show the correctly registered methods, static analysis employed by IDEs such as PyCharm would fail to resolve the correct signature. The solution: Stub files according to PEP484. These can be picked up by IDEs implementing the standard, however, dynamic resolution is now impossible as pyi interface files do not allow for runtime code to dynamically omit signatures. Long story short and following the Zen of Python: Explicit is better than implicit. So I went with explicit method definitions for each sub handler and threw exceptions on invalid chain-endpoint combinations.
This bears two major advantages: Code completion and runtime-checks are still available through IDEs and interactive shells, and developers are notified early if they are using an invalid API call, even before the request is sent. This adds a bit more robustness to the library.
Minor Obstacles
There were minor pain points during the implementation that I thought are worth sharing.
- Amberdata uses MythX for automated smart contract security checks on Ethereum Mainnet and Rinkeby. This endpoint returns empty response bodies for non-Ethereum chains (where smart contracts don’t exist), instead of a valid message body containing an error along with a verbose message for the developer.
- The endpoint for token price information returns a 400 (Bad Request) if there is no price information available for the specified token address. Following best practices, a 404 (Not Found) would be more appropriate here as the request might be valid but the backend simply lacks the data to process it.
- The API documentation does not make clear which REST endpoint is supported by which blockchain. Once I finished the first implementation, I simply wrote a script that checks all endpoints with all available chains, printing out an overview of supported endpoints (basically filtering out 444 Not Supported return codes).
- Various endpoints (such as the logs for a smart contract address) return a JSON error response stating “request was invalid or cannot be served. See message for details”, however the message key inside the response carries an empty string.
- .. and the most obvious challenge in trying to implement a full-fledged API client: There are a lot of endpoints, and each of them can be hit with a different chain. Orchestrating these calls in a client library can be very rough if the developer has not spent enough time about their software architecture. This could also make it harder for developers to support new endpoints or blockchains in the future because it suddenly might require deep code changes. Luckily, the official JavaScript library (while here and there hard to read), provides a good starting point. A general blog article about client library integration would have saved me some troubles along the way, however. 🙂
I hope that the Amberdata team can pick up on some of these issues (even though I might be nitpicking here), and provide a smoother integration experience. As a backend engineer, I definitely sympathise with the problem of always double- and triple-checking your work, testing over and over again, and making sure things are smooth for developers – no matter what their requirements might be.
TESTS, TESTS, TESTS, TESTS, TE…
The good thing about having the same functionality for multiple groups of chains? Parametrised tests. In no time I wrote 667 unit tests covering 100% of the client library’s branches, including the few edge cases our client business logic encompasses.
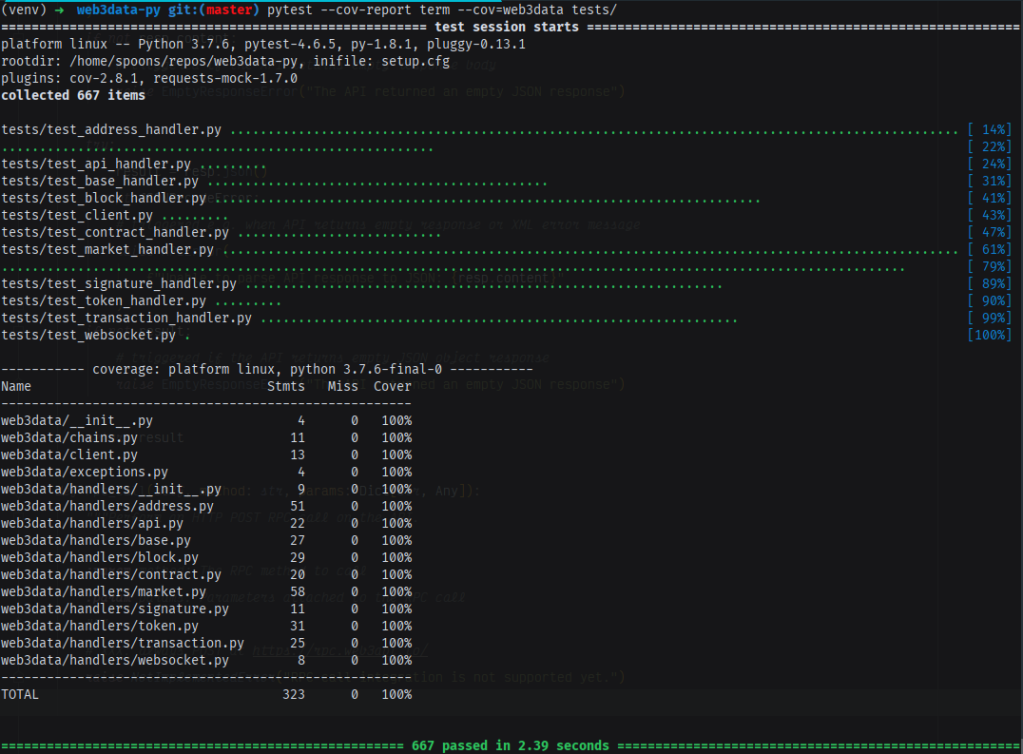
A decent coverage metric is one more indicator that we have a production-ready package in front of us.
Documentation
Each method inside of web3data-py is fully documented. This includes additional keyword arguments used for filtering the results. The docstrings are mainly based on the Amberdata API reference, including some extra notes where necessary. This fulfills another quality indicator: At the time of initial release, the web3data-py project contains 706 lines of code, and 832 lines of docstrings. The existing code is rigorously documented in each file, and additionally elaborated on in the Sphinx documentation hosted on ReadTheDocs. It is worth noting that this step took the most time to finish.
Endgame
For the last stage I planned the usual stuff I do when building Python libraries. My tools of the trade are:
- bumpversion: Allows for easy release management by replacing strings across the project. Also automatically creates tags and commits.
- PyUp: Automatically update Python dependencies and opening pull requests on the repository to upgrade things.
- Travis: My CI service of choice – free for open-source projects and pretty on the YAML side.
- Sphinx: The Python gold standard for documentation, and quick to get started with thanks to Autodoc.
- ReadTheDocs: Easy and painless hosting, free for open-source projects and integrates perfectly with the default Sphinx build pipeline.
- Coveralls: A service to keep track of coverage metrics, integrates very well with Travis.
- Cookiecutter (pypackage): Always helps to quickly set up a new Python package. Some manual assembly is required here, but the more you do it, the easier it becomes.
- Black: Automatic formatting for great good!
- isort: Alphabetically sort imports to satisfy my tingling sense of German order.
Retrospectively, the endgame was mainly focused on getting things in order. Setting up service integrations, getting CI and automatic package publishing to work, hosting the RTD documentation, getting Autodoc to work, slapping badges in the repo’s readme file, etc.
Future Work
Let’s not forget I have a day job and need to bring home the bacon. Nonetheless, if time allows, I would like to extend this project with two more features:
- RPC calls
- Websocket subscriptions
Especially the last one is a feature where the Amberdata API manages to shine. It would be a shame not to have support for it on board. With the additional tooling such as broad unit tests running regularly on CI, automatic dependency updates, easy release management, etc. on board, I am confident that I can keep maintaining this package – and that’s what I call a great hackathon outcome.
I hope that you, the reader, will find joy in this package. Please don’t hesitate to show me what you have built with it on Twitter!
Happy Hacking!

2 thoughts on “The Web3 API has come to Python!”
Comments are closed.